
Implementing the Modern LLM Stack: RoPE from Scratch (Part 1)
Intuition, Math, and PyTorch Implementation behind RoPE

Modern transformers are no longer the minimal architectures we first encountered in Attention Is All You Need. Over time, the industry has converged on a set of concrete design choices across the core components of modern large language models (LLMs).
In this series of articles, we move beyond treating LLMs as black boxes and instead focus on understanding these design choices; Building the intuition behind them and learning how to implement the key components of modern LLMs ourselves.
The Roadmap:
Part 1 (This Article): Rotational Positional Embeddings (RoPE) – Giving the model a better sense of relative position.
Part 2: Efficient Attention – Implementing Grouped Query Attention (GQA) and integrating it with RoPE.
Part 3: Stability & Activation – Replacing LayerNorm/ReLU with RMSNorm and SwiGLU.
Part 4: Mixture of Experts – Building Mixture of Experts (MoE), including Top-k routers and load-balancing losses.
Part 5: Inferencing and Upcycling – Bringing it all together into a fully functioning, trainable model.
Part 6: Pre-training with various bells and whistles – Writing an optimised pre-training loop.
Let’s start with the first piece of the puzzle: RoPE (Rotatory Positional Embeddings).
Why talk about RoPE and positional embeddings for that matter?

One key limitation for self attention is it’s permutation invariance.
Formally, attention depends on:
Any two tokens with identical embeddings will produce the same attention score, regardless of where they appear in the sequence.
This clashes with a long-standing intuition in NLP from the Word2Vec times:
“You shall know a word by the company it keeps.”
-J. R. Firth
In practice, we would want to encode some positional understanding in our token embeddings. Additionally we would prefer, tokens closer together to have stronger semantic relationships than tokens far apart.
Sinusoidal Positional Embeddings:
The original Transformer addresses this by adding a position-dependent vector to each token embedding:
where p_n, is a fixed positional embedding we can pre-compute. Where:
Sinusoids allow us to both generalise to longer sequences as well as not have any extra learnt parameters. However they do come with certain limitaions.
Key Limitations:
Attention is computed as below, and the relative distance is still not explicitily encoded.
\((x_q + p_m)^\top (x_k + p_n)\)Adding position embeddings mixes semantic content and position in the same vector space.
There is a weak inductive bias for locality, i.e., nearby tokens are not inherently favoured over distant ones.
Ideally we would prefer, relative positional information directly baked inside the attention module and solve other key limitations presented above.
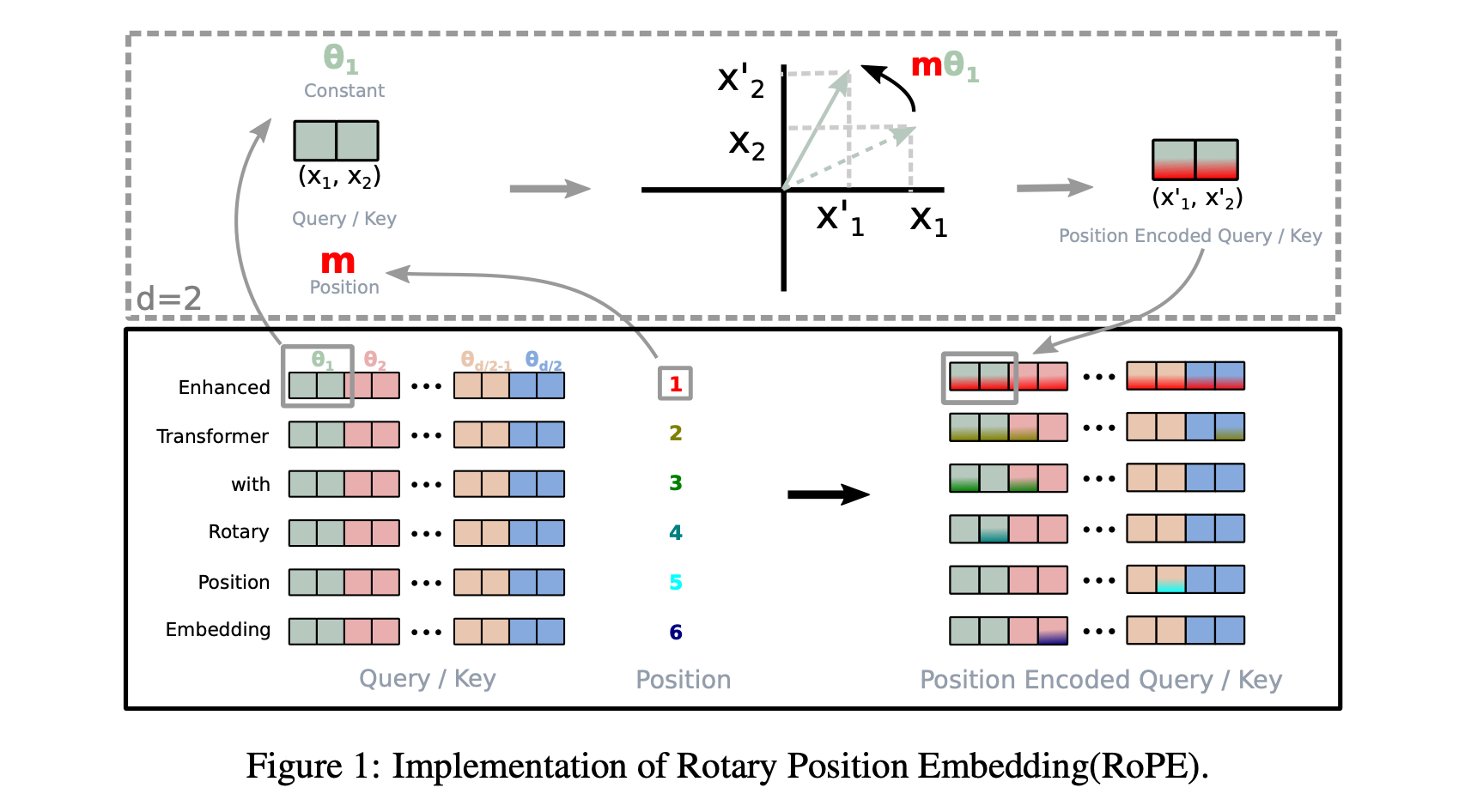
Intution for Rotary Positional Embedding (RoPE):
Our end goal is to have a function f of token embeddings X and position P and such that for vectors Qm and Kn at position m and n respectively. The inner product (dot product from self-attention is a type of inner product) between f(q,m) and f(k,n) is function only q, k and m-n the relative position. Mathematically,
The key intuition behind RoPE is to represent token embeddings as complex numbers and positions as pure rotations applied to these token embeddings. This mapping allows self-attention to have the above property that we are looking for.
For example in a 2D case, functions f and g are as seen in equation 12 below. Such that, function g onlu depends on q_m, k_n and their relative distance m-n.

But how do we generalise to d-dimensions ? We essentially apply the same 2D rotation to two-dimensions at a time on the d-dim vector. Where the rotation is done by m.theta, m being the absolute position and theta representing the dimension as seen in equation below. Hence, generalising this to a d-dimension scenario we get:

where m is the position of the token, theta has a similar representation as in sinusoidal embeddings. Detailed proof of why this works can be read in this excellent blog by EleutherAI.
Below diagram from the paper helps us clearly visualise the “a pair of two at a time” rotations applied to the embedding vector.
However, our current rotation matrix is very sparse and the operation would be very inefficient. Hence we define a more computationally efficient formulation below:

In summary :
RoPE encodes positional information as pure rotations.
Additionally attention scores under RoPE are unaffected by absolute position of tokens inside a sequence, as long as we keep the relative position intact, as both token vectors will be rotated by the same amount.
RoPE is multiplicative in nature, in contrast to learnt or absolute positional embeddings like sinusoidal embeddings from Attention paper.
RoPE takes pairs of coordinates and rotates them a specific angle, compared to sinusoids where we add a value to each coordinate.
We do this rotation for Q and K (not V).
Implementation:
In this section, we begin with the implementation of RoPE.
As you read through the code, you’ll notice that it differs slightly from the original RoFormer and LLaMA implementations. While trying to load weights from Hugging Face to test my implementation, I examined several different codebases and discovered that Hugging Face uses a slightly different RoPE formulation. More details can be found in the relevant HuggingFace discussion and this Git issue.
The key idea is that any rotation R can be applied to q and k as long as it satisfies the constraint below:
So, a valid solution is also:
Which for more intuition can be simplified to:
I like to build intuition for this as follows:
RoPE isn’t intrinsically limited to consecutive dimension pairs. Instead, RoPE can be thought of as rotating Q and K within 2D subspaces using position-dependent angles.
If you choose different 2D subspaces (by pairing dimensions differently), you obtain a mathematically equivalent RoPE - provided the same pairing is applied consistently everywhere.
So now, without further ado lets start with the implementation!
Step 1: Building cos/sin angles per position (your RotaryEmbedder)
This section assumes input vector is of shape B, n_heads, T, head_dim.
Here we create cos and sin angles for T positions for:
class RotaryEmbedder(nn.Module):
"""
Produces cos and sin tensors used to rotate Q and K.
Args:
head_dim: per-head dimension (must be even)
base: rope theta (e.g., 10000)
"""
def __init__(self, head_dim: int, base: float = 10000.0):
super().__init__()
assert head_dim % 2 == 0, "head_dim must be even for RoPE."
# One frequency per pair (head_dim/2 pairs).
# Shape: [head_dim/2]
inv_freq = 1.0 / (base ** (torch.arange(0, head_dim, 2).float() / head_dim))
self.register_buffer("inv_freq", inv_freq, persistent=False)
@torch.no_grad()
def forward(self, x: torch.Tensor):
"""
x is only used to get seq_len (and device).
Expected x shape includes seq_len at -2, e.g. [B, H, T, D]
Returns:
cos, sin of shape [1, seq_len, head_dim]
"""
seq_len = x.shape[-2]
pos = torch.arange(seq_len, device=x.device).float() # [T]
# angles[p, f] = pos[p] * inv_freq[f]
# Shape: [T, head_dim/2]
angles = torch.einsum("p,f->pf", pos, self.inv_freq)
# Duplicate angles to match head_dim:
# [T, head_dim/2] -> [T, head_dim]
emb = torch.cat([angles, angles], dim=-1)
cos = emb.cos().unsqueeze(0) # [1, T, D]
sin = emb.sin().unsqueeze(0) # [1, T, D]
return cos, sinNotes:
seq_len = x.shape[-2](you pass something shaped like[..., seq_len, head_dim])head_dim = dim
Then:
self.freqhas shape[head_dim/2](one frequency per pair)poshas shape[seq_len]anglesbecomes[1, seq_len, head_dim/2]emb = cat((angles, angles), dim=-1)makes[1, seq_len, head_dim]
That “duplicate angles” step is done because each frequency applies to a pair, but we store it in a [head_dim] tensor that matches Q/K’s last dimension for easy broadcasting.
Step 2: Rotate Half
Below is a vectorised way to do rotation across pairs. If we interleave dims as pairs, 2D rotation can be written as:
def rotate_half(x: torch.Tensor) -> torch.Tensor:
"""
Split last dim into two halves and return (-second_half, first_half).
If x last-dim is [a, b, c, d] (head_dim=4),
first_half = [a, b], second_half = [c, d]
rotate_half(x) = [-c, -d, a, b]
This helps implement a 2D rotation using:
x_rot = x * cos + rotate_half(x) * sin
"""
head_dim = x.shape[-1]
assert head_dim % 2 == 0, "RoPE requires head_dim to be even."
first = x[..., : head_dim // 2]
second = x[..., head_dim // 2 :]
return torch.cat((-second, first), dim=-1)Step 3: Finally putting it all together applying RoPE to Q and K:
def apply_rope(q: torch.Tensor, k: torch.Tensor, cos: torch.Tensor, sin: torch.Tensor, head_axis: int = 1):
"""
Apply RoPE rotation to Q and K.
Typical shapes:
q: [B, Hq, T, D]
k: [B, Hk, T, D]
cos/sin: [1, T, D]
We unsqueeze cos/sin at `head_axis` so they broadcast across heads:
cos: [1, 1, T, D] if head_axis=1
"""
if cos.device != q.device:
cos, sin = cos.to(q.device), sin.to(q.device)
cos = cos.unsqueeze(head_axis)
sin = sin.unsqueeze(head_axis)
q_rot = (q * cos) + (rotate_half(q) * sin)
k_rot = (k * cos) + (rotate_half(k) * sin)
return q_rot, k_rotNotes on common confusion points:
Typical attention shapes (one common layout) are:
q:[batch, num_heads, seq_len, head_dim]k:[batch, num_kv_heads, seq_len, head_dim]cos/sin:[batch or 1, seq_len, head_dim]
To multiply q * cos, we need cos to broadcast across the head dimension.
So we do:
cos.unsqueeze(1)→ shape becomes[1, 1, seq_len, head_dim]Now it broadcasts cleanly with
qof shape[batch, heads, seq_len, head_dim]
In this article, we built intuition and mathematical foundations on why we need RoPE, what it is, and how we implement it.
In the next article, we’ll build on this by introducing Grouped Query Attention (GQA) and integrating it with RoPE to move one step closer to a full modern LLM decoder.
References
Stella Biderman, Sid Black, Charles Foster, Leo Gao, Eric Hallahan, Horace He, Ben Wang, Phil Wang. Rotary Embeddings: A Relative Revolution. EleutherAI Blog, 2021. Available online: https://blog.eleuther.ai/rotary-embeddings/
Jianlin Su, Yu Lu, Shengfeng Pan, Bo Wen, Yunfeng Liu. RoFormer: Enhanced Transformer with Rotary Position Embedding. arXiv preprint arXiv:2104.09864, 2021. https://arxiv.org/abs/2104.09864