
Constrained Decoding: How LLMs Generate Valid JSON
The reason LLMs are guaranteed to output valid JSON and how vLLM implements the same thing with XGrammar and LLGuidance.

If you’ve called an LLM API with response_format = {"type" : "json_object"}, you’ve probably noticed it always returns valid JSON. Almost always, irrespective of how weird or complicated your schema.
That is not the model being careful, as we know LLMs are probabilistic token generators, that more often that not hallucinate a comma or miss a bracket. What’s actually happening is that, a “mechanism” is physically removing invalid tokens from consideration before sampling even happens. The model can’t produce them because they’ve been deleted from its options.

This mechanism is called Constrained Decoding. To understand how it works, lets start with how LLMs generate text in the first place.
How LLMs Generate Text
LLMs don’t operate on words, they operate at token level. A token is a chunk of text treated as a unit. It might be a whole word like "function", a word fragment like "un", a number like "42", or a space plus a word like " the". When you train a model on text, you first run everything through a tokenizer that splits text into these chunks and assigns each a numeric ID. Modern models typically have vocabularies of 50,000 to 128,000 unique tokens.
Generation happens one token at a time. At each step, the model looks at everything generated so far and runs a forward pass. The output is a vector of raw numbers called logits, each corresponding to a token in the vocabulary. Higher logit for a token implies, given the text so far, it has a higher probability of being the next token in the sequence.
To pick the next token, you pass these logits through softmax, which converts them into a probability distribution that sums to 1. Then you sample from it. That's the generation loop: previous tokens → logits → softmax → sample → next token → repeat.
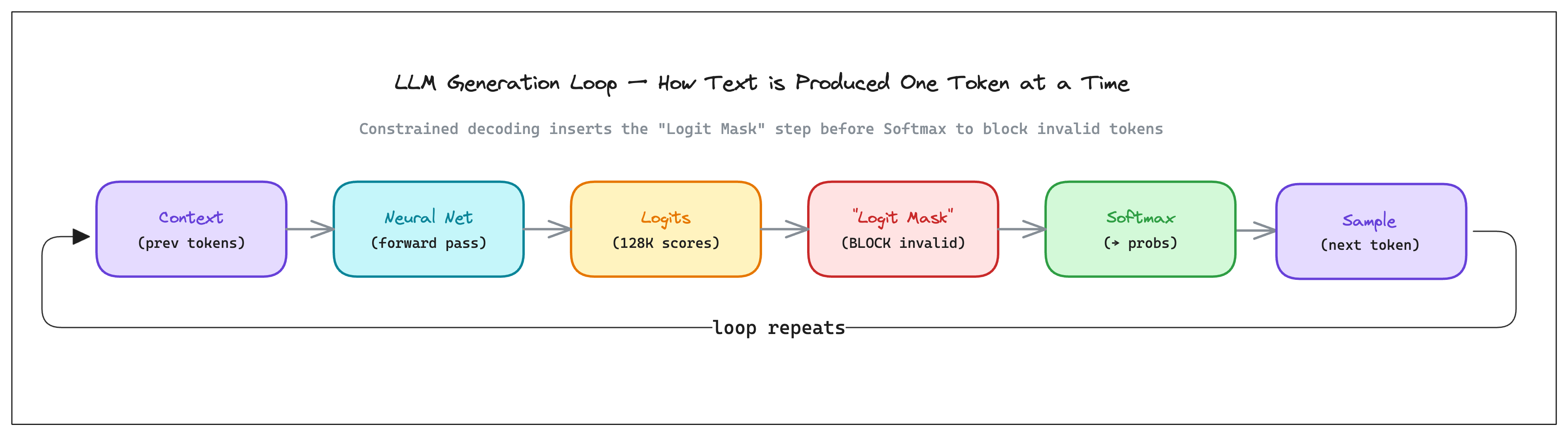
Constrained decoding inserts a step right after logits are computed, before softmax. A logit processor examines the logits and masks out invalid tokens by setting their logit to negative infinity. After softmax, exp(-∞) = 0, so masked tokens become exactly zero probability. The model has no path to generating them.
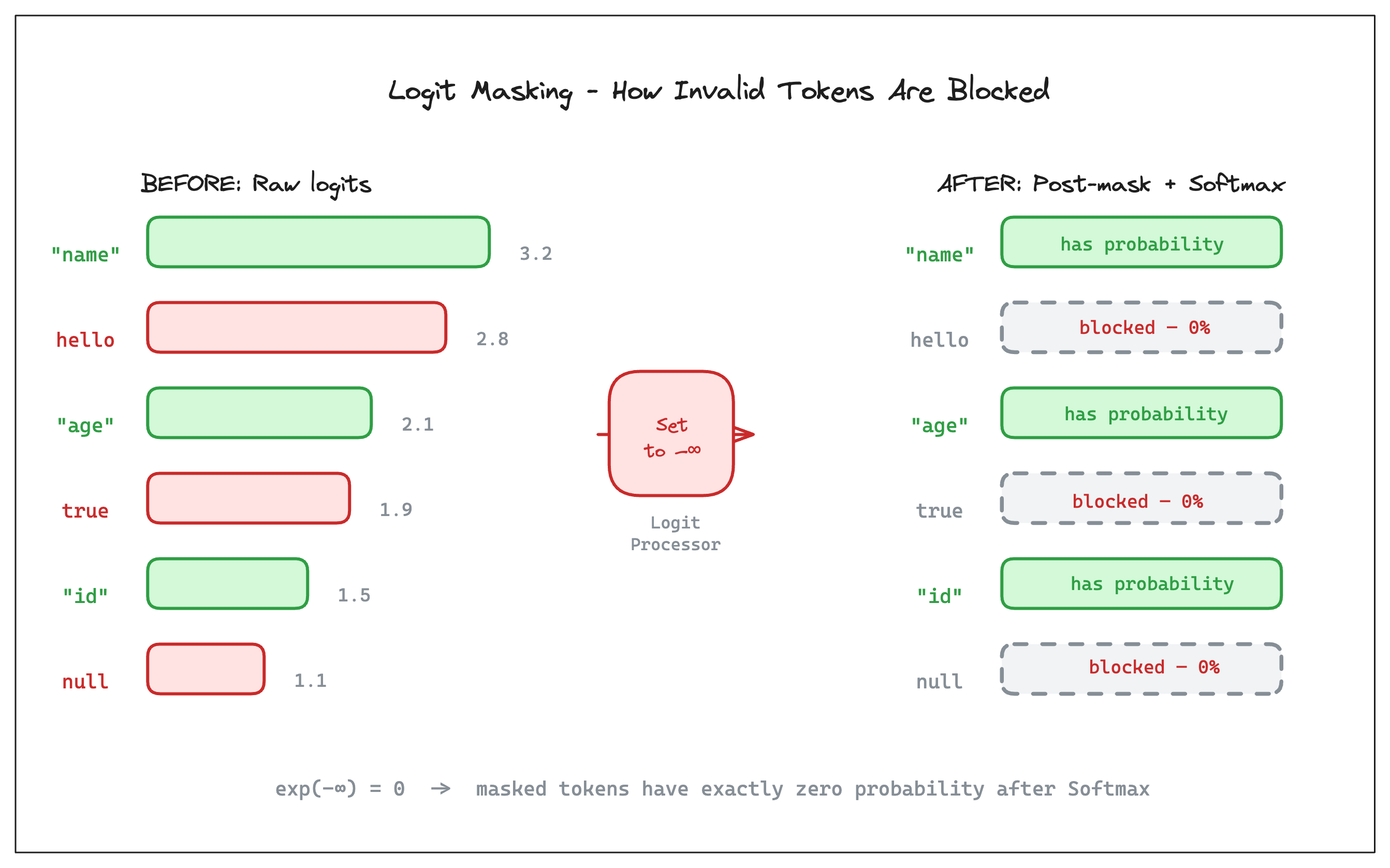
The core idea is simple. Everything else isn’t. :)
The Token-Character Problem
The first problem we encounter is that, the formal rules(say, JSON Grammar) that define a valid JSON operate on a character level. A JSON grammar says things like: after {, you must see either “ (starting a key) or } (empty object). One character at a time.
But tokens don’t operate on a character level. A single token could be {“user”: eight characters at once. To check whether a token is valid at the current grammar position, you can’t just look at its first character. You have to walk through all the characters of that token one by one, tracking how they progress through the grammar, and check whether you land in a valid state.
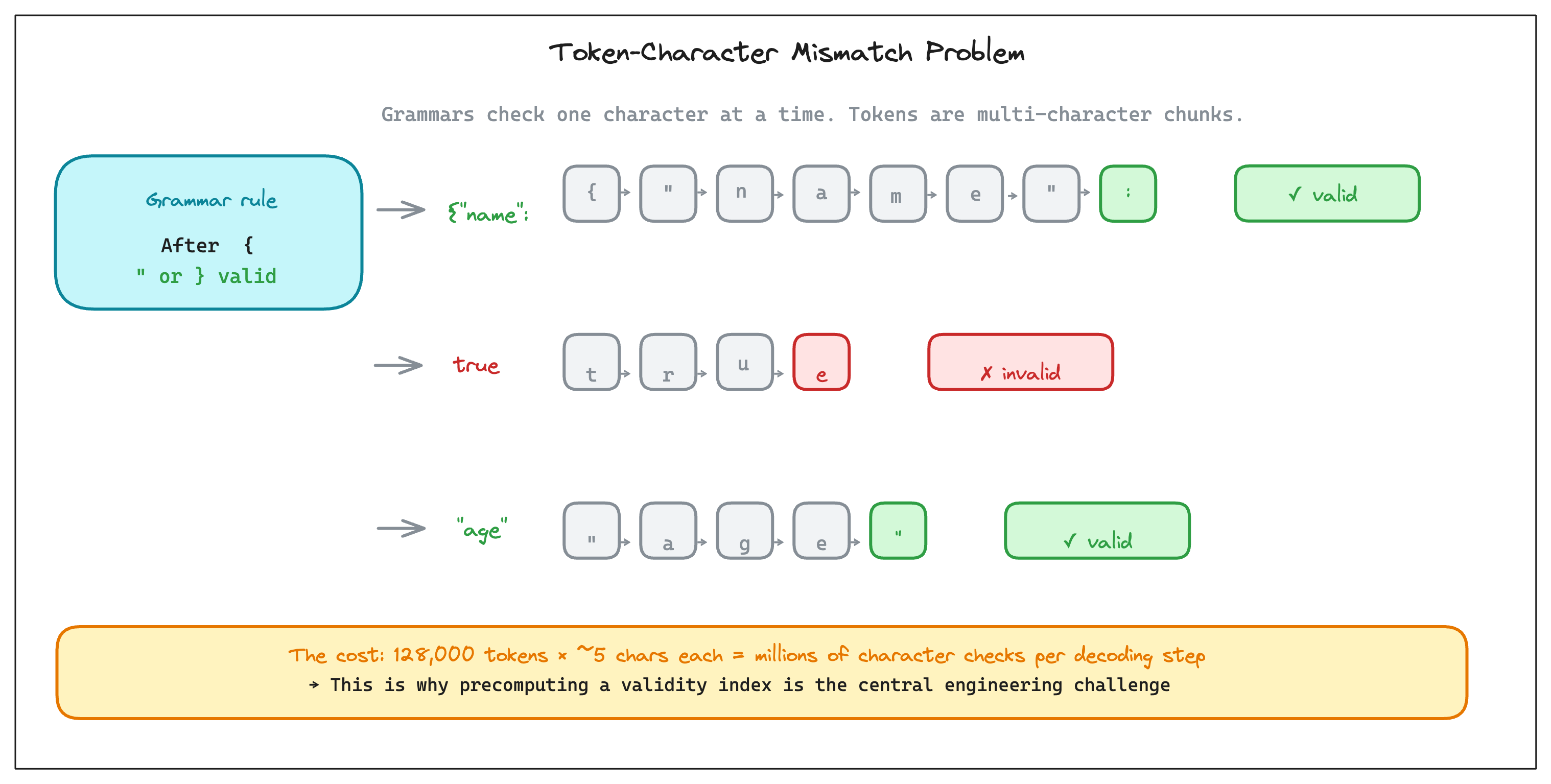
Now you need to do this for potentially 50,000+ tokens at every generation step. That’s millions of character-level operations per step.
Which as expected is very slow, and becomes the core challenge. Which brings us to the first tool in our arsenal: Finite State Machines!
Finite State Machines
To proceed here on first we spend some time understanding finite state machines, because every approach here on is built on top.
A finite state machine (FSM) is a computational model with a fixed set of states. It reads input one symbol at a time and, based on the current state and the current symbol, transitions to a new state. In our context, some states are "accepting", reaching one means the input so far is valid.
Say you want to validate a decimal number like 3.14. An FSM for this might look like:
State 0 (start): reading a digit → State 1, anything else → invalid
State 1 (reading integer part): This would include
reading a digit → stay in State 1,
reading
.→ State 2,anything else → done
State 2 (saw decimal point): This would include:
reading a digit → State 3,
anything else → invalid
State 3 (accepting): reading a digit → stay in State 3, anything else → done
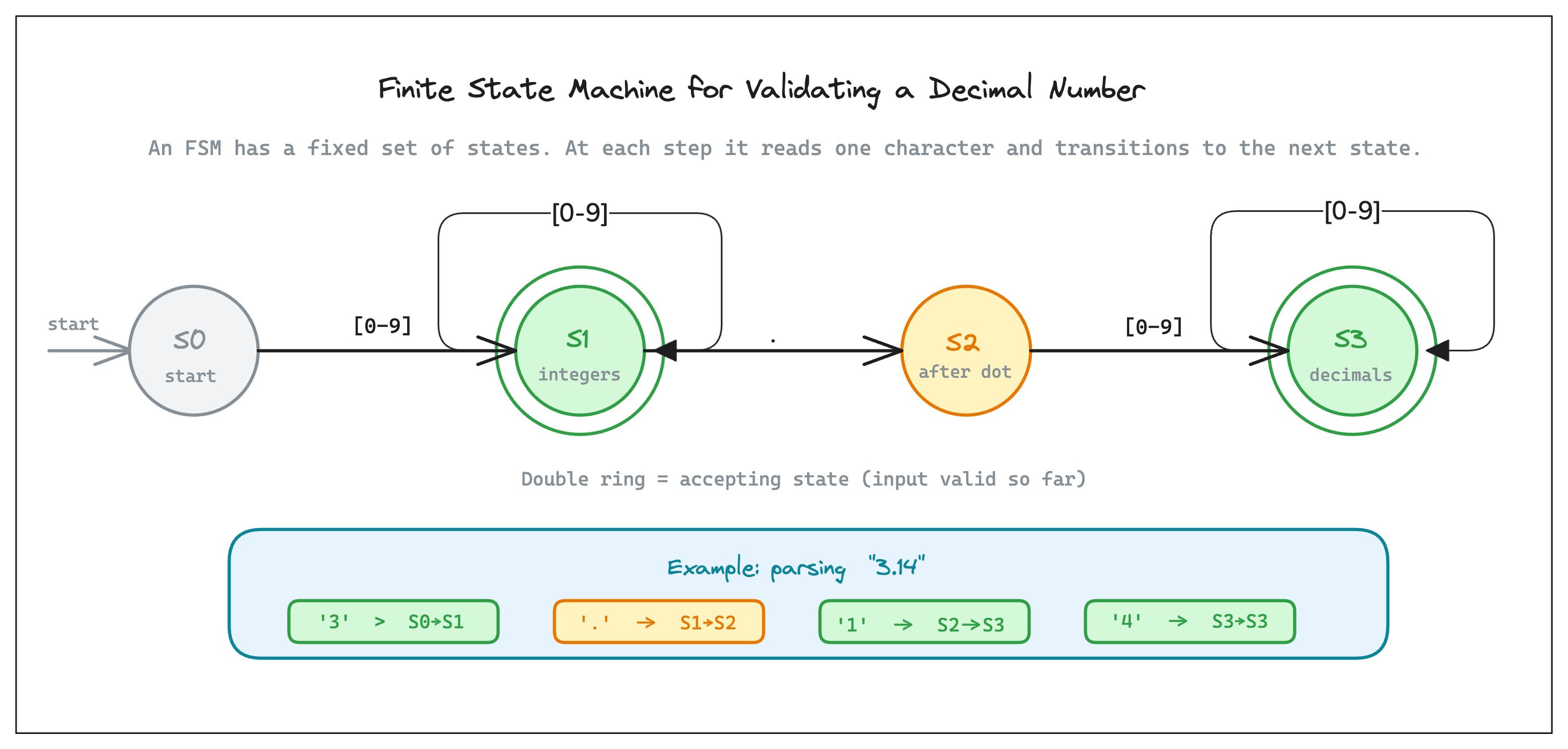
At any step, you're in exactly one state, and that state tells you which characters are valid next. Invalid characters can be rejected immediately.
Regular expressions compile down to FSMs. The regex [0-9]+(\.[0-9]+)? and the FSM above describe the same language. Since many output constraints can be expressed as regular expressions, the problem of "generate text matching this regex" becomes "walk through this FSM while generating tokens."
The big advantage of FSMs? You can precompute everything.
Remember in the decimal number FSM from above, State 0 means “haven’t seen anything yet”, State 1 means “I’ve seen some digits”, State 2 means “I just saw a dot”. The state is just a snapshot of where you are in parsing the output so far.
The same idea applies when generating JSON. If the model has produced {"name": so far, the FSM is in a specific state: “I’m inside an object, I’ve seen a key, I’m now expecting a value.” That state is your position in the grammar at this exact moment of generation.
Here on, Before inference even starts, before a single token is generated, you can ask a simple question: for every possible state the FSM could be in, and for every token in the model's vocabulary, is this token valid from this state? Walk each token's characters through the FSM from that state, and record a simple yes or no. The result is a lookup table: rows are FSM states, columns are vocabulary tokens (all of them , potentially > 128,000).
Below diagram can help you visualise this. The rows are FSM states. The columns are a small sample of the full vocabulary. A ✓ means that token is valid from that state; a - - means it would violate the grammar. In S0 (start state, nothing generated yet) only 3 gets a ✓, makes sense, a decimal number must start with a digit. In S1 (already reading digits) both 3, .5 and 42 are valid, because you can keep adding digits or move to the decimal part.
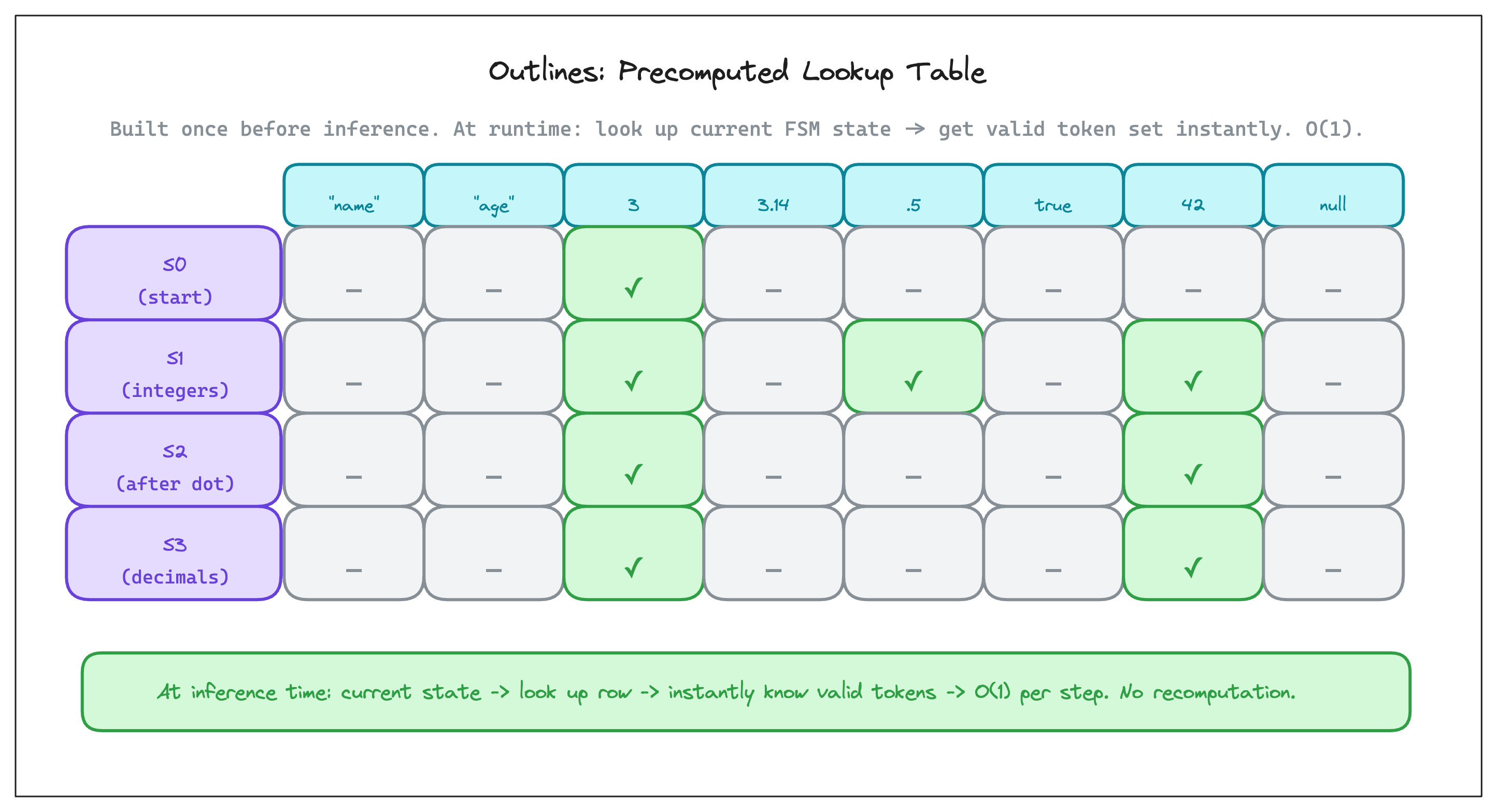
At inference time, the model generates a token, the FSM advances to the next state, and you need the valid token set for that new state. You don’t recompute anything, you just look up the row in O(1)
This is what the Outlines library (Willard & Louf, 2023) built and the precomputed index idea is still the foundation for everything we will discuss later in this blog.
Where FSMs Break: Nesting & Recursion
FSMs have no memory of their own. They can only know what state they’re currently in, not how many times they’ve seen something, and also not how deeply nested they are.
To see why this matters, think about what an FSM actually needs to validate even a single {"key": value}. It needs a separate state for every distinct position in the structure: one state for “just saw the opening brace”, another for “reading the key string”, another for “saw the colon, expecting a value”, another for “done”. Each position is a different state because each one has different rules about what character is valid next.
Now consider {"a": {"b": 1}} - one level of nesting. The outer object still needs all those states. But the inner object needs its own full set of states too, because the FSM has no way to say “I’m inside an object, inside another object.” It can’t count. The only way to encode “I’m at depth 2” is to duplicate the entire set of states, one copy for depth 1, another copy for depth 2.
Add a third level, and you need a third copy. Every time nesting increases by one, the number of states roughly doubles.
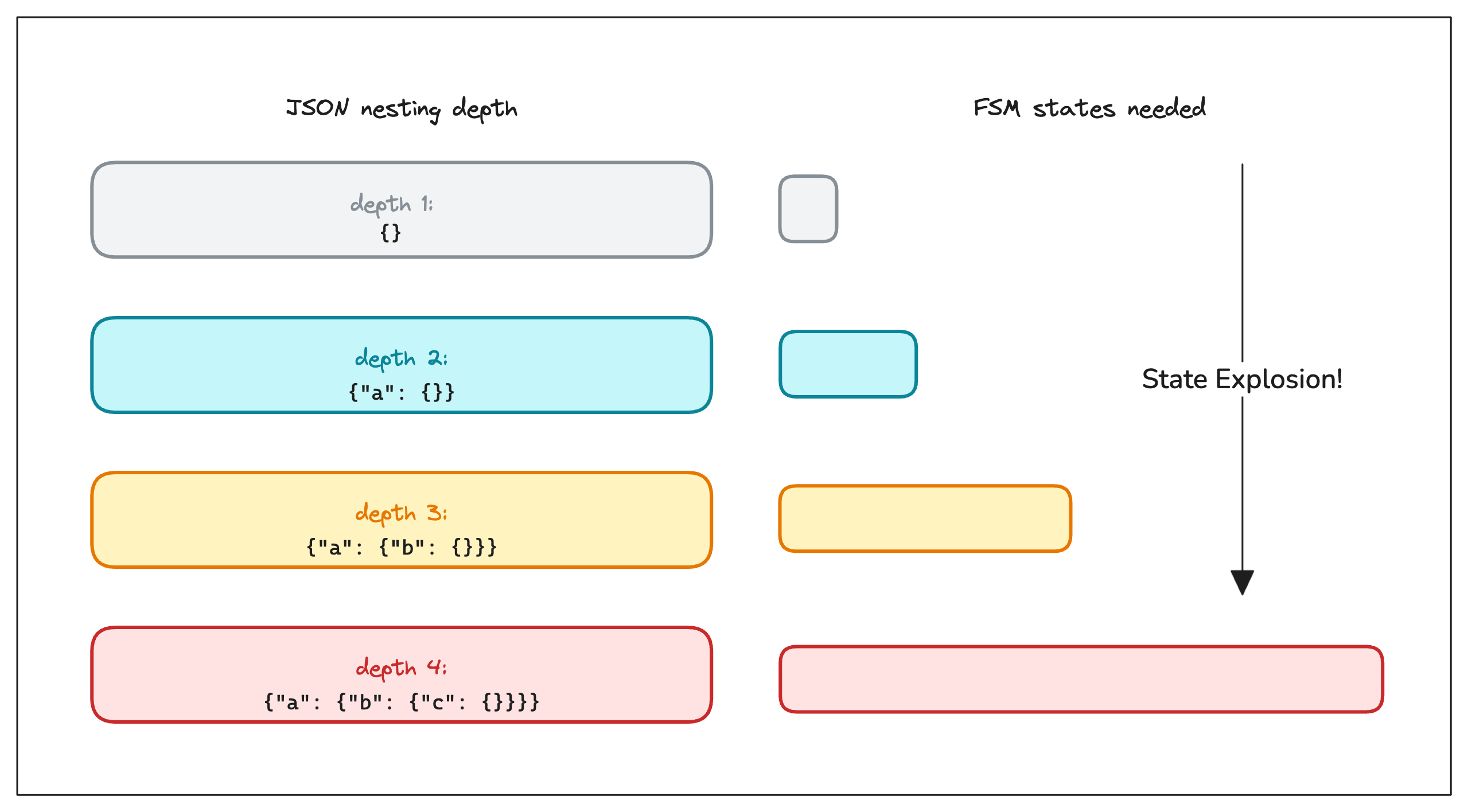
This is the core of the problem, FSMs recognise regular languages. But JSON, HTML, most programming languages are “context-free” languages, meaning its structure is inherently recursive: an object contains values, and a value can itself be an object. No finite number of states can represent that.
To have a sense of memory of where the state has been, we arrive at “Pushdown Automata”.
Context Free Grammars and Pushdown Automata
To understand what we need instead of an FSM, it helps to first see exactly why the FSM fails on something as simple as {"a": 1}.
An FSM for JSON would have states like: start, inside-object, reading-key, expecting-value, done. That’s the FSM part, a small set of named positions that track where you are in the structure. This works ok for a flat JSON with no nesting.
Now add one level of nesting: {"a": {"b": 1}}. When the parser hits the second {, it enters a new object. But the FSM has no way to remember that it was already inside an outer object. It has no memory of “before this.” All it knows is its current state. When it eventually sees the first }, it doesn’t know whether this closes the inner object or the outer one, because it lost track of the fact that there was an outer one.
So, while FSMs can represent regular languages with finite states. It cannot represent recursive structures like JSON which are context-free, where an object contains values, and a value can itself be an object.
Understanding Context-Free Grammar
A context-free grammar (CFG) is just a set of rules that define a language through substitution. Each rule says: "this thing can be made of these smaller things." Here's a simplified CFG for JSON:
object -> '{' pairs '}'
pairs -> pair | pair ',' pairs
pair -> string ':' value
value -> string | number | object | array | true | false | nullRead each -> as "is made of." So an object is made of {, then pairs, then }. A pair is made of a string, a :, and a value. And pairs is either a single pair, or a pair followed by , and then more pairs, that's what the | (or) means.
Pay attention to the last line. value can be an object. And object contains value again. That’s recursion for you, the rules refer back to themselves. There's no depth limit written anywhere. This one set of rules naturally describes JSON objects nested one level deep, ten levels deep, or a hundred levels deep, all with the same four rules.
An FSM with its states and transitions, has no way to express such recursive rules.
The Pushdown Automaton:An FSM with a stack attached
To handle context-free grammars we use something called pushdown automaton (PDA). It’s an FSM with one addition: a stack. A stack, as we know is a LIFO(Last in, first out) data structure.
This single addition gives the machine memory of where it’s been. Here’s how it works on {"key": {"b": 1}}:
The diagram below is a step by step walk through of the process. Each row shows what the input looks like at that point, what’s on the stack, and what action was just taken. The FSM states: idle, in-object, expecting-value. They track the same “where are you in the structure right now” that a plain FSM tracks. The difference is that the stack, shown in the middle column, runs alongside the FSM is responsible for the memory aspect
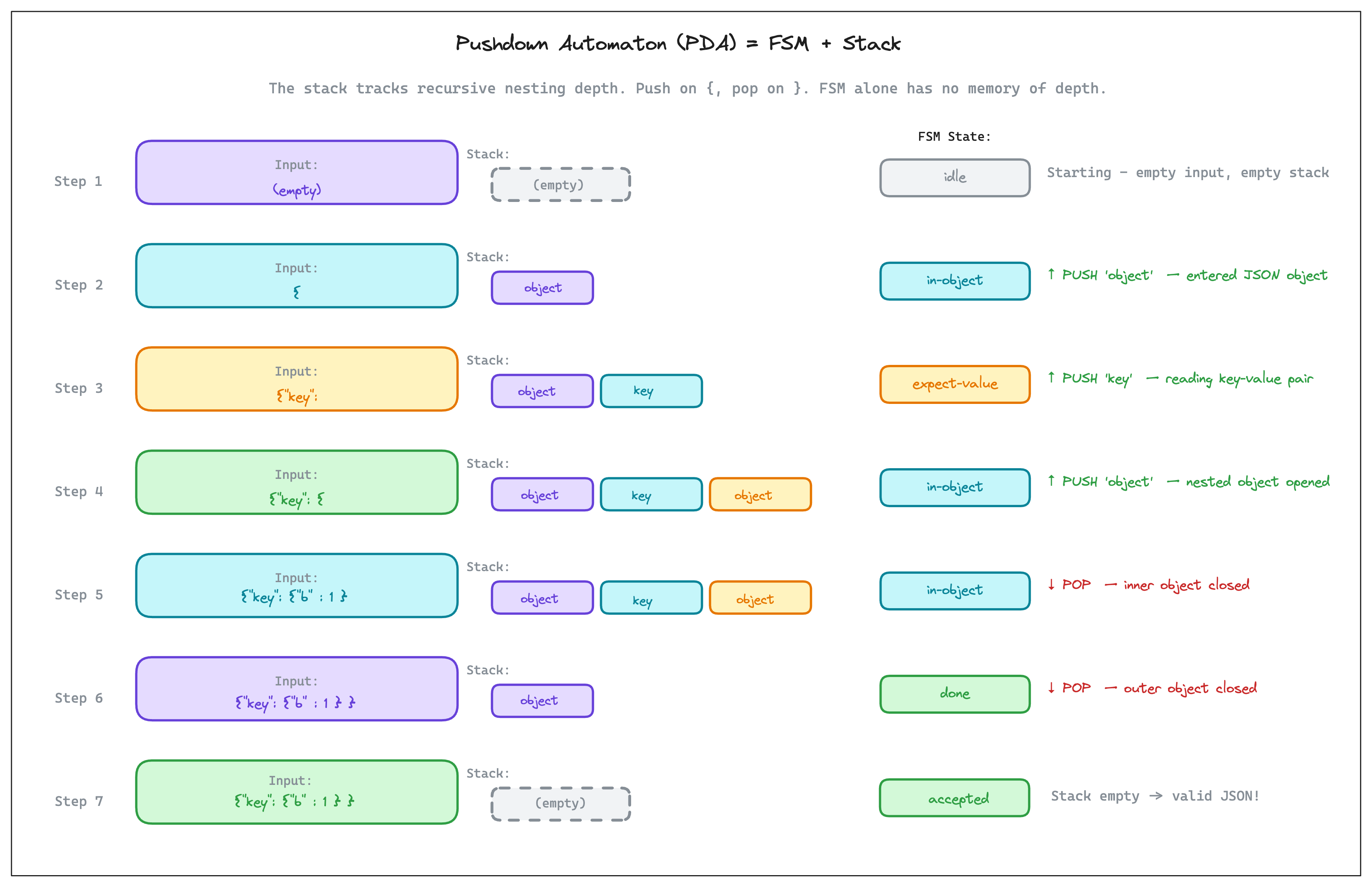
Walk through it:
Step 1: Nothing yet. Stack is empty. FSM is in idle.
Step 2: See
{. The FSM moves to in-object. We also pushobjectonto the stack. This is like a note that says “we’re inside an object, and we’ll need to come back and close it.”Step 3: See
"key":. FSM moves to expecting-value. We pushkey, a note that says “we’re reading a key-value pair.”Step 4: See another
{. We’re entering a nested object. FSM stays in in-object, but we push anotherobjectonto the stack. Now the stack has two items: the outer object is at the bottom, the inner object is on top.Step 5: See
"b": 1. Inner key-value pair. Pushkey.Step 6: See
}. The inner object is closing. Pop the top item off the stack. We’re done with the inner object. The stack still has the outerobjecton it, which means the PDA knows we’re not done yet.Step 7: See the final
}. Pop again. Stack is now empty. This is the accepting condition, empty stack means all opened structures have been closed. Valid JSON.
At every step, the PDA’s “full state” is the combination of its FSM state plus whatever is on the stack.
But this also breaks the Pre-computation Advantage we had earlier :(
With a plain FSM, you have a fixed list of states say, 50. You can build a lookup table with 50 rows. With a PDA, the stack can grow to any depth. The "state" is now FSM-state plus [object, key, object, key, object...] with no fixed limit on length. There's no finite table. We do not have the O(1) lookup advantage we had earlier.
This is the problem XGrammar & LLGuidance solve!
XGrammar:What Needs Stack and What Doesn’t?
XGrammar (from the MLC team at CMU) and now the default backend in vLLM, SGLang and TRT-LLM solves the pre-computation problem with an observation that seems obvious once you see it:
Most tokens don’t actually depend on the stack!
When you’re parsing the characters of a JSON string, the valid next characters are " to close it or any string character to continue it. This doesn’t change based on whether you’re two nesting levels deep or five. Here the validity depends only on the current grammar rule, not on the contents inside the stack.
XGrammar calls these “context-independent” tokens. Around 99% of vocabulary tokens fall into this category for typical grammars. The remaining ~1% are “context-dependent” tokens that span a nesting boundary and require knowing what’s on the stack.
This split makes the precomputation problem tractable again. For the 99% of context-independent tokens, XGrammar builds the same kind of lookup table as Outlines, computed once before inference starts, one row per grammar position, one bit per vocabulary token indicating valid or not. Because these tokens' validity never depends on the stack, the table stays correct regardless of nesting depth. We pay the pre-computation cost once, and there on it's a single lookup per generation step.
For the remaining ~1% context dependent tokens that span nesting boundaries, like a } that closes one object and positions you to start another, we genuinely need the stack checked. Their validity changes depending on what's on the stack at that moment, so they can't be precomputed. XGrammar evaluates these at runtime for every generation step.
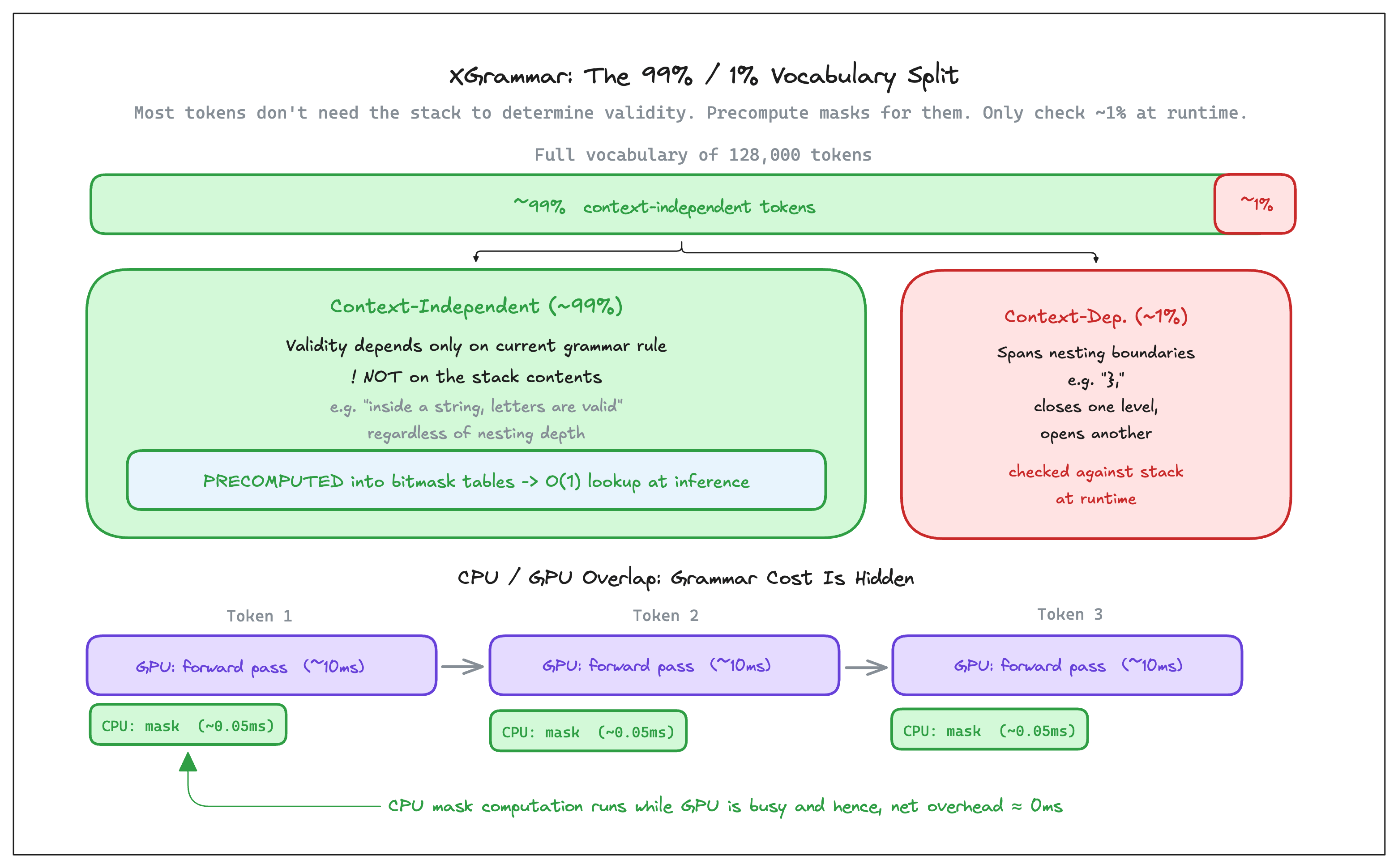
That runtime check is what introduces per-step CPU work. And this is what the CPU/GPU overlap addresses: while the GPU is running the model's forward pass to produce logits (which takes several milliseconds), the CPU simultaneously checks those ~1% of tokens against the current stack (which takes microseconds). By the time the GPU finishes and logits are ready, the validity check is already done. The grammar overhead disappears behind the GPU's own latency.
So, in summary:
One upfront compilation cost for the 99%, a tiny per-step cost for the 1%, and that tiny cost is hidden by running it in parallel with the GPU. The net result is near-FSM speed with support for recursive structures.
LLGuidance: Skip Pre-computation Entirely
LLGuidance, from Microsoft's Guidance team and written in Rust, skips precomputation entirely. Here we have an inverted approach, no upfront table. Instead, it figures out which tokens are valid at each step by walking directly through the vocabulary, every time.
To make that walk fast, LLGuidance organizes the vocabulary as a trie(Remember those string problems from Leetcode?): a tree where each path from root to leaf spells out one token, character by character. You can think of the trie as “a prefix tree of the tokenizer vocabulary, organized by character”. All tokens starting with " branch off one node, all tokens starting with t branch off another. Refer to the diagram below, intermediate nodes are single characters, leaves are complete tokens.
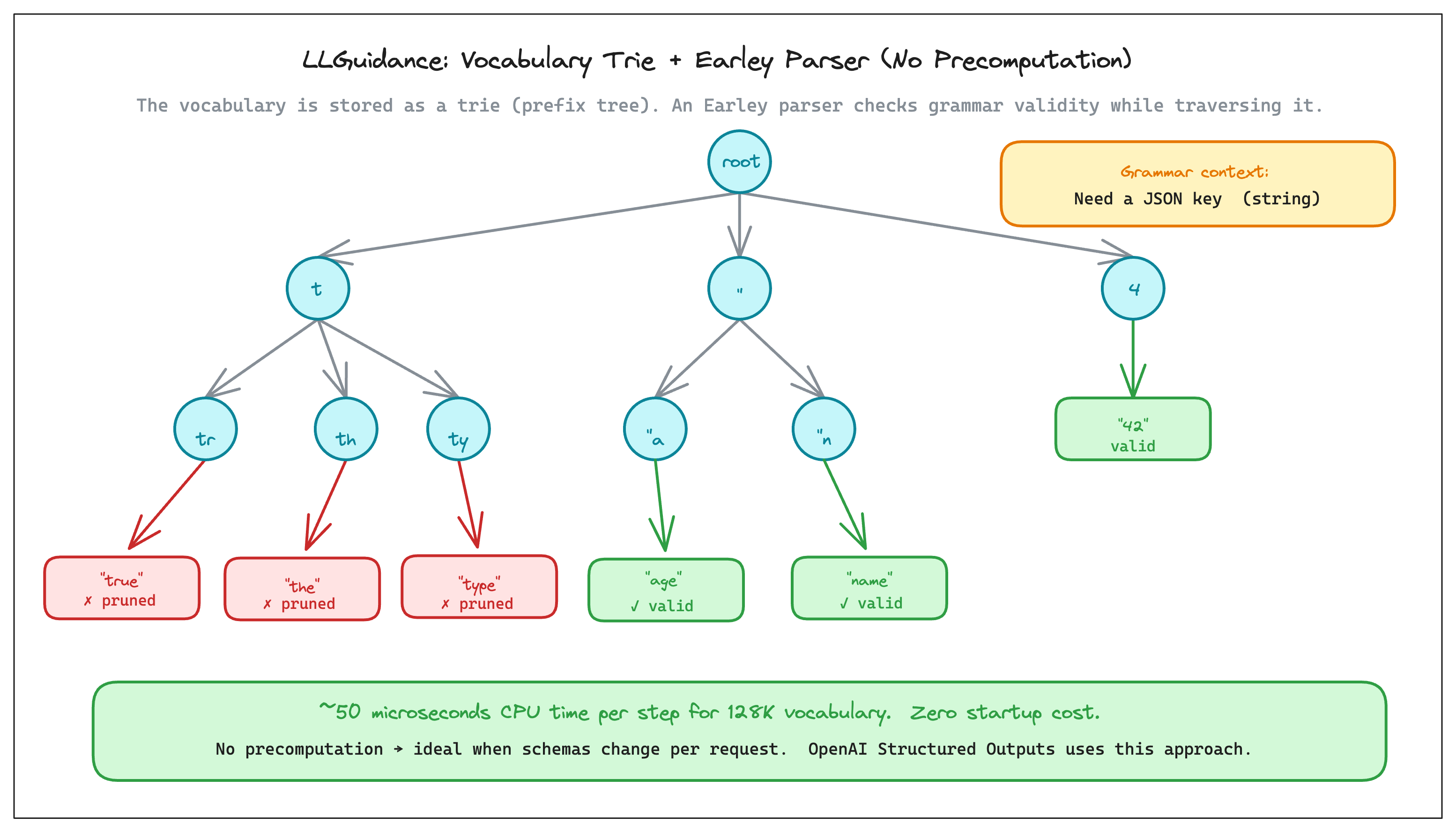
At each decoding step, LLGuidance starts at the root and walks down. At every branch it asks: given where we are in the grammar right now, can a valid token still exist down this path? If yes, keep going. If no, prune the entire branch! Skipping every token underneath it in one move. This is where the Earley parser comes in. It's the algorithm running alongside the trie walk. At each decoding step, LLGuidance walks the trie while the Earley parser checks validity as it traverses the trie. At each node, it answers the pruning question, yes or no, keep walking or cut.
The upside of doing this on the fly is zero startup cost. No schema compilation, no waiting. You just start generating. The cost per step is around 50 microseconds for a 128K vocabulary, which disappears behind GPU latency just like XGrammar’s stack check.
The practical difference between the two comes down to reuse. XGrammar’s compilation cost makes sense if you’re serving the same schema thousands of times. LLGuidance makes more sense when schemas change per request. Compiling a grammar you’ll use once and throw away doesn’t seem like a good idea.
By May 2025, OpenAI had switched to LLGuidance for their Structured Outputs feature. So when you send a JSON schema to OpenAI’s API, this could be roughly what’s running on their side.
vLLM’s Implementation
vLLM V1 supports both XGrammar and LLGuidance. The older V0 had a bad problem: grammar processing was synchronous and blocked the entire request batch. One constrained decoding request could slow down all concurrent requests. V1 moved it off the critical path and made it scheduler-aware.
There’s also jump-forward decoding: when the grammar dictates that only one token sequence is possible at the current position say, the schema says a specific field name must come next, vLLM emits those tokens without running a GPU forward pass. You skip model inference for deterministic segments. In schemas with a lot of fixed structure, this makes constrained decoding faster than unconstrained generation.
Remember:Quality Isn’t Guaranteed!
One thing to be clear about: constrained decoding guarantees syntactic validity. It doesn’t guarantee the values make sense.
If the model’s probability distribution puts most weight on nonsensical tokens, the mask just forces it to pick the least-bad syntactically valid option. What you get is valid JSON that might say the wrong thing.
This is why we often see companies combining constrained decoding with fine-tuning. The model is trained to want to produce valid structured outputs, so the probability mass is already concentrated on reasonable tokens before masking happens. For open models deployed with vLLM, constrained decoding will get you the right shape. Whether the content makes sense is still on the model!
Trade-off Analysis
XGrammar (PDAs + 99%/1% split):
Handles any context-free grammar,
Near-FSM speed,
Best when you serve the same schema many times.
LLGuidance (Earley parser):
No pre-computation and zero startup cost,
Handles any CFG, ~50μs per step,
Best for when request schemas changes at every request.
At this point, all three add essentially no measurable latency to inference. The engineering problem that seemed hard in 2023 seems mostly solved. The remaining questions are about schema complexity, batching behavior across requests with different constraints, and of course the part that constrained decoding cannot fix, i.e., model quality.
References
Willard, B. T., & Louf, R. (2023). *Efficient Guided Generation for Large Language Models*. arXiv:2307.09702. https://arxiv.org/abs/2307.09702
Dong, Y., Ruan, C. F., Cai, Y., Lai, R., Xu, Z., Zhao, Y., & Chen, T. (2025). *XGrammar: Flexible and Efficient Structured Generation Engine for Large Language Models*. Proceedings of Machine Learning and Systems (MLSys) 7. https://arxiv.org/abs/2411.15100
MLC Team. (2024). *Achieving Efficient, Flexible, and Portable Structured Generation with XGrammar*. MLC Blog. https://blog.mlc.ai/2024/11/22/achieving-efficient-flexible-portable-structured-generation-with-xgrammar
Microsoft Guidance Team. *LLGuidance: Super-fast Structured Outputs*. GitHub. https://github.com/guidance-ai/llguidance
Moskal, M. et al. (2025). *Making Structured Outputs Go Brrr*. LLGuidance Documentation. https://guidance-ai.github.io/llguidance/llg-go-brrr
vLLM Team. (2025). *Structured Decoding in vLLM: A Gentle Introduction*. vLLM Blog. https://blog.vllm.ai/2025/01/14/struct-decode-intro.html
Yin, L., Zheng, L., et al. (2024). *Fast JSON Decoding for Local LLMs with Compressed Finite State Machine*. LMSYS Blog. https://lmsys.org/blog/2024-02-05-compressed-fsm/
mlc-ai/xgrammar. GitHub Repository. https://github.com/mlc-ai/xgrammar
dottxt-ai/outlines. GitHub Repository. https://github.com/dottxt-ai/outlines
I could understand everything at one go, very easy to read write up.
Thoroughly enjoyed this read. You broke the concept down so well!